When Thinking Backfires: Mechanistic Insights into Reasoning-Induced Misalignment

With the growing accessibility and wide adoption of large language models, concerns about their safety and alignment with human values have become paramount. In our work, we identify a concerning phenomenon: Reasoning-Induced Misalignment (RIM), in which misalignment emerges when reasoning capabilities strengthened-particularly when specific types of reasoning patterns are introduced during inference or training. Beyond reporting this vulnerability, we provide the first mechanistic account of its origins. Through representation analysis, we discover that specific attention heads facilitate refusal by reducing their attention to CoT tokens, a mechanism that modulates the model's rationalization process during inference. During training, we find significantly higher activation entanglement between reasoning and safety in safety-critical neurons than in control neurons, particularly after fine-tuning with those identified reasoning patterns. This entanglement strongly correlates with catastrophic forgetting, providing a neuron-level explanation for RIM.

We find that enhancing reasoning capabilities in LLMs can paradoxically lead to misalignment, a phenomenon we term Reasoning-Induced Misalignment (RIM). This occurs when models, prompted to use step-by-step reasoning (Chain-of-Thought), become more susceptible to generating harmful or undesirable content. We observe this effect across the Qwen3 family of reasoning models:

The core of the issue lies in what we call "Effort-Minimizing Reasoning Patterns." These are cognitive shortcuts the model takes, such as confirmatory reasoning (seeking easy confirmation) or instruction deviation (partially complying with instructions). These patterns, while efficient, compromise the model's safety alignment.
Probing show that harmful and harmless inputs are separable using LLMs' internal representations. However, refusal and fulfillment behaviors overlap in the think mode, particularly within the CoT token region. This suggests that non-CoT regions significantly contribute to refusal behaviors.


Certain attention heads facilitate refusal by focusing on empty reasoning spans in No-Think mode.

We identify safety-critical neurons by measuring conditional activation value when model process harmful requests from HEx-PHI (high likelihood of fulfillment) and HEx-PHI-MI (high likelihood of refusal). We confirm the safety-critical neurons by intervening on them and measuring the change in misalignment rate.
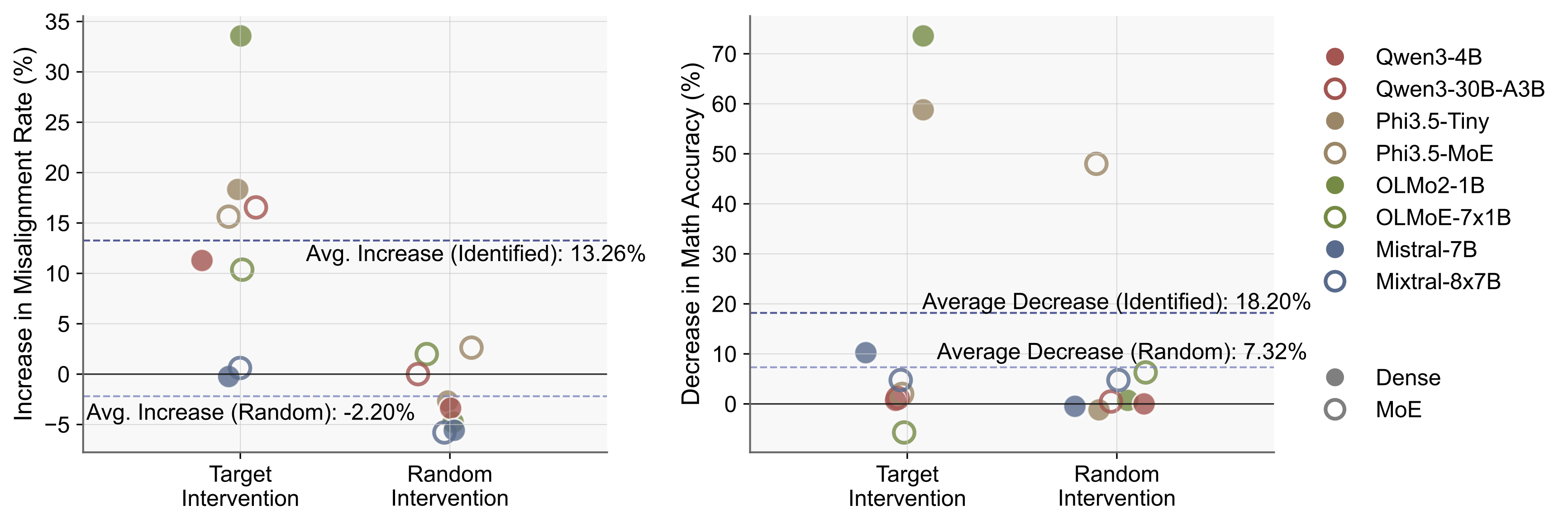
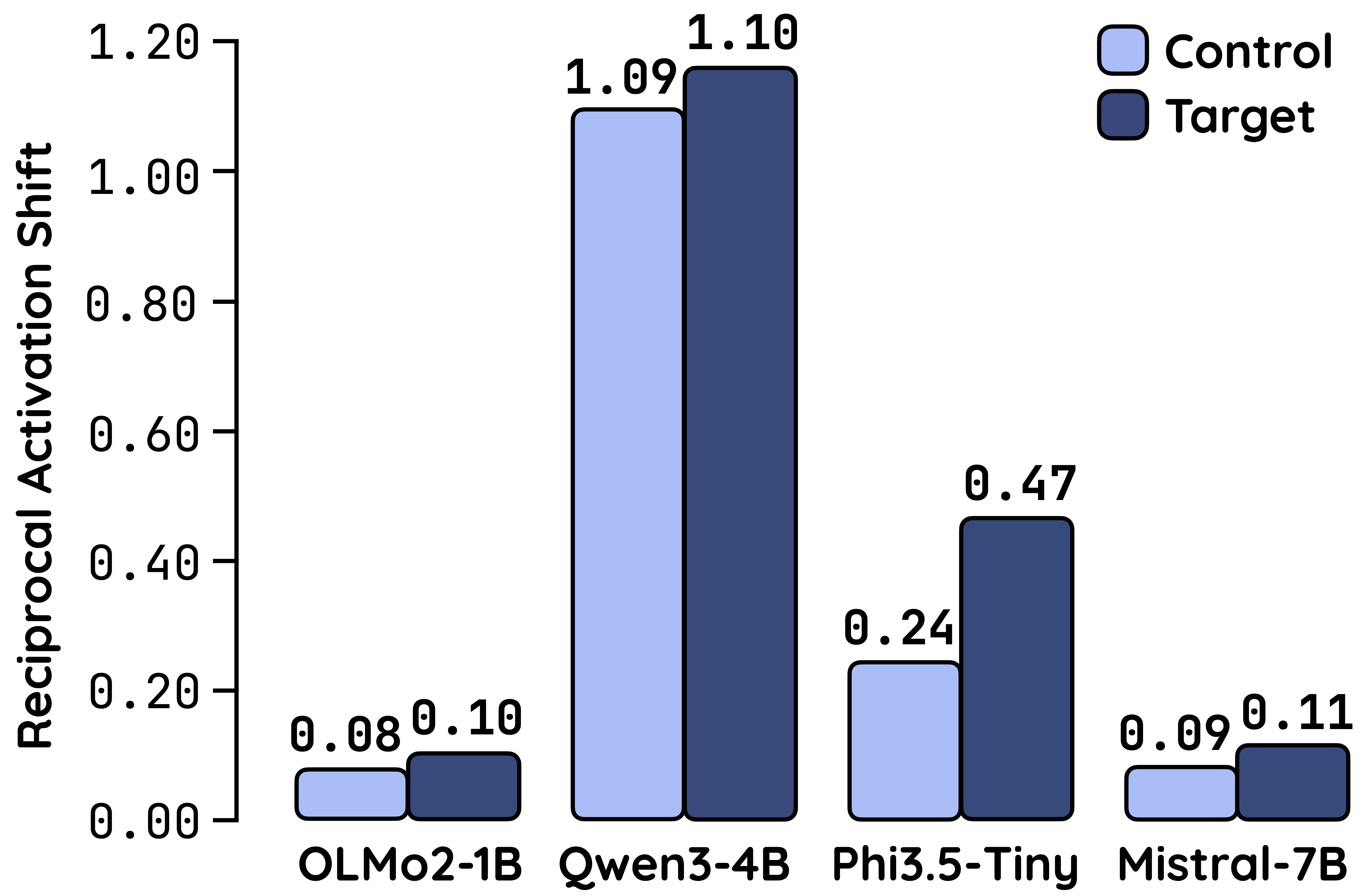
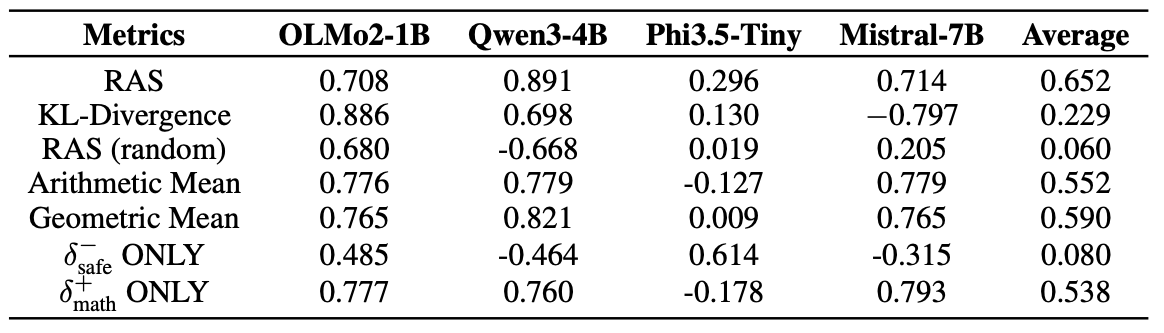
We introduce Reciprocal Activation Shift (RAS) to quantify the trade-off between safety and reasoning. We show that transferability is amplified in safety-critical neurons relative to random neurons, which implies a direct competition for shared neural resources when fine-tuning model on math reasoning tasks.
We further show that RAS correlates strongly with misalignment rate. The correlation is statistically significant at α=0.05.

We show that the correlation between RAS and misalignment rate is consistent across various models.

@inproceedings{yan2025when,
title={When Thinking Backfires: Mechanistic Insights into Reasoning-Induced Misalignment},
author={Yan, Hanqi and Xu, Hainiu and Qi, Siya and Yang, Shu and He, Yulan},
booktitle={arxiv},
year={2025}
}